云计算底层技术-netfilter框架研究
netfilter框架
netfilter是linux内核中的一个数据包处理框架,用于替代原有的ipfwadm和ipchains等数据包处理程序。netfilter的功能包括数据包过滤,修改,SNAT/DNAT等。netfilter在内核协议栈的不同位置实现了5个hook点,其它内核模块(比如ip_tables)可以向这些hook点注册处理函数,这样当数据包经过这些hook点时,其上注册的处理函数就被依次调用,用户层工具像iptables一般都需要相应内核模块ip_tables配合以完成与netfilter的交互。netfilter hooks、ip{6}_tables、connection tracking、和NAT子系统一起构成了netfilter框架的主要部分。可以参考Netfilter Architecture了解更多内容
下面这张图来自维基百科netfilter,它展示了netfilter框架在协议栈的位置,你们可能发现这张图在我的博客中出现多次了,那是因为这张图太经典了。它可以清楚地看到netfilter框架是如何处理通过不同协议栈路径上的数据包
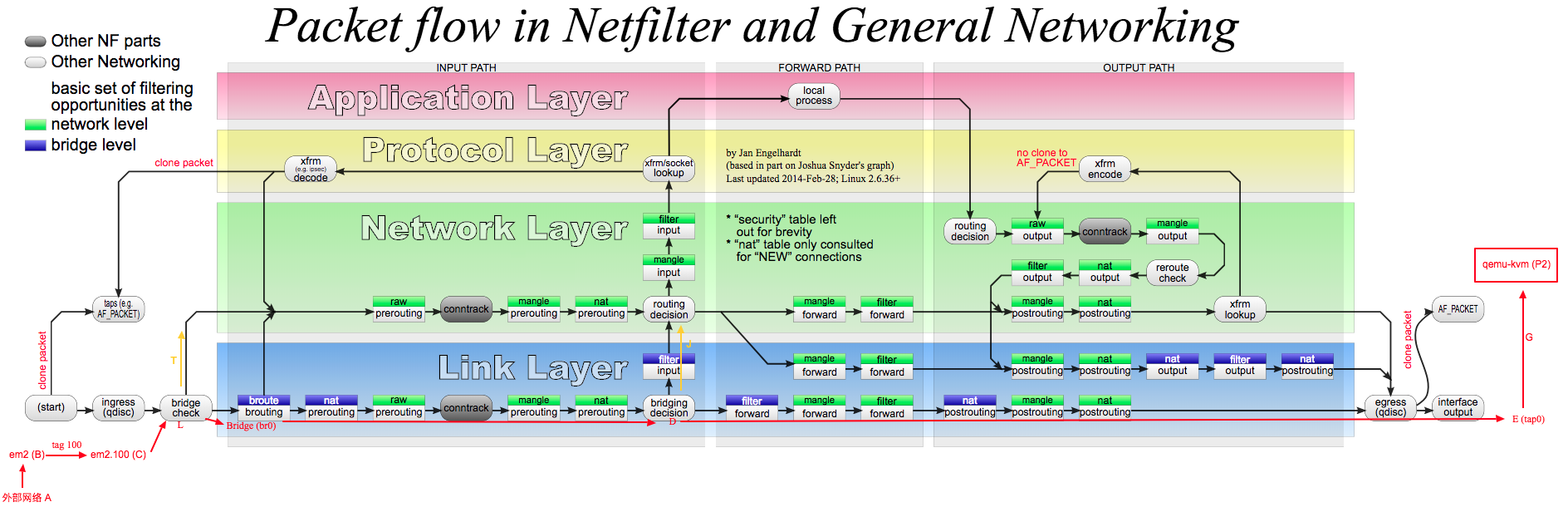
我们知道iptables的定位是IPv4 packet filter,它只处理IP数据包,而ebtables只工作在链路层Link Layer处理的是以太网帧(比如修改源目mac地址)。图中用有颜色的长方形方框表示iptables或ebtables的表和链,绿色小方框表示network level,即iptables的表和链。蓝色小方框表示bridge level,即ebtables的表和链,由于处理以太网帧相对简单,因此链路层的蓝色小方框相对较少。
我们还注意到一些代表iptables表和链的绿色小方框位于链路层,这是因为bridge_nf代码的作用(从2.6 kernel开始),bridge_nf的引入是为了解决在链路层Bridge中处理IP数据包的问题(需要通过内核参数开启),那为什么要在链路层Bridge中处理IP数据包,而不等数据包通过网络层时候再处理呢,这是因为不是所有的数据包都一定会通过网络层,比如外部机器与主机上虚拟机的通信流量,bridge_nf也是openstack中实现安全组功能的基础。
bridge_nf代码有时候会引起困惑,就像我们在图中看到的那样,代表iptables表和链的绿色小方框跑到了链路层,netfilter文档对此也有说明ebtables/iptables interaction on a Linux-based bridge
It should be noted that the br-nf code sometimes violates the TCP/IP Network Model. As will be seen later, it is possible, f.e., to do IP DNAT inside the Link Layer
ok,图中长方形小方框已经解释清楚了,还有一种椭圆形的方框conntrack,即connection tracking,这是netfilter提供的连接跟踪机制,此机制允许内核”审查”通过此处的所有网络数据包,并能识别出此数据包属于哪个网络连接(比如数据包a属于IP1:8888->IP2:80这个tcp连接,数据包b属于ip3:9999->IP4:53这个udp连接)。因此,连接跟踪机制使内核能够跟踪并记录通过此处的所有网络连接及其状态。图中可以清楚看到连接跟踪代码所处的网络栈位置,如果不想让某些数据包被跟踪(NOTRACK),那就要找位于椭圆形方框conntrack之前的表和链来设置规则。conntrack机制是iptables实现状态匹配(-m state)以及NAT的基础,它由单独的内核模块nf_conntrack实现。下面还会详细介绍
接着看图中左下方bridge check方框,数据包从主机上的某个网络接口进入(ingress), 在bridge check处会检查此网络接口是否属于某个Bridge的port,如果是就会进入Bridge代码处理逻辑(下方蓝色区域bridge level), 否则就会送入网络层Network Layer处理
图中下方中间位置的bridging decision类似普通二层交换机的查表转发功能,根据数据包目的MAC地址判断此数据包是转发还是交给上层处理,具体可以参考我另一篇文章linux-bridge
图中中心位置的routing decision就是路由选择,根据系统路由表(ip route查看), 决定数据包是forward,还是交给本地处理
总的来看,不同packet有不同的packet flow,packet总是从主机的某个接口进入(左下方ingress), 然后经过check/decision/一系列表和链处理,最后,目的地或是主机上某应用进程(上中位置local process),或是需要从主机另一个接口发出(右下方egress)。这里的接口即可以是物理网卡em1,也可以是虚拟网卡tun0/vnetx,还可以是Bridge上的一个port。
上面就是关于这张图的一些解释,如果还有其它疑问,欢迎留言讨论,下面说说netfilter框架的各个部分
connection tracking
当加载内核模块nf_conntrack后,conntrack机制就开始工作,如上图,椭圆形方框conntrack在内核中有两处位置(PREROUTING和OUTPUT之前)能够跟踪数据包。对于每个通过conntrack的数据包,内核都为其生成一个conntrack条目用以跟踪此连接,对于后续通过的数据包,内核会判断若此数据包属于一个已有的连接,则更新所对应的conntrack条目的状态(比如更新为ESTABLISHED状态),否则内核会为它新建一个conntrack条目。所有的conntrack条目都存放在一张表里,称为连接跟踪表
那么内核如何判断一个数据包是否属于一个已有的连接呢,我们先来了解下连接跟踪表
连接跟踪表
连接跟踪表存放于系统内存中,可以用cat /proc/net/nf_conntrack查看当前跟踪的所有conntrack条目。如下是代表一个tcp连接的conntrack条目,根据连接协议不同,下面显示的字段信息也不一样,比如icmp协议
ipv4 2 tcp 6 431955 ESTABLISHED src=172.16.207.231 dst=172.16.207.232 sport=51071 dport=5672 src=172.16.207.232 dst=172.16.207.231 sport=5672 dport=51071 [ASSURED] mark=0 zone=0 use=2
每个conntrack条目表示一个连接,连接协议可以是tcp,udp,icmp等,它包含了数据包的原始方向信息(蓝色)和期望的响应包信息(红色),这样内核能够在后续到来的数据包中识别出属于此连接的双向数据包,并更新此连接的状态,各字段意思的具体分析后面会说。连接跟踪表中能够存放的conntrack条目的最大值,即系统允许的最大连接跟踪数记作CONNTRACK_MAX
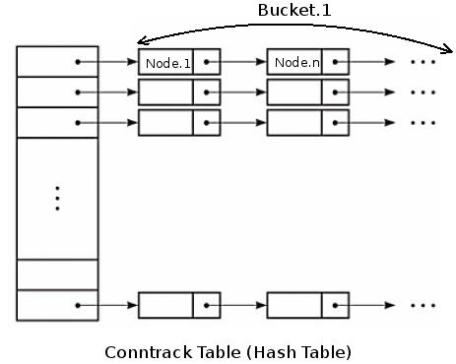
在内核中,连接跟踪表是一个二维数组结构的哈希表(hash table),哈希表的大小记作HASHSIZE,哈希表的每一项(hash table entry)称作bucket,因此哈希表中有HASHSIZE个bucket存在,每个bucket包含一个链表(linked list),每个链表能够存放若干个conntrack条目(bucket size)。对于一个新收到的数据包,内核使用如下步骤判断其是否属于一个已有连接:
- 内核提取此数据包信息(源目IP,port,协议号)进行hash计算得到一个hash值,在哈希表中以此hash值做索引,索引结果为数据包所属的bucket(链表)。这一步hash计算时间固定并且很短
- 遍历hash得到的bucket,查找是否有匹配的conntrack条目。这一步是比较耗时的操作,
bucket size越大,遍历时间越长
如何设置最大连接跟踪数
根据上面对哈希表的解释,系统最大允许连接跟踪数CONNTRACK_MAX = 连接跟踪表大小(HASHSIZE) * Bucket大小(bucket size)。从连接跟踪表获取bucket是hash操作时间很短,而遍历bucket相对费时,因此为了conntrack性能考虑,bucket size越小越好,默认为8
#查看系统当前最大连接跟踪数CONNTRACK_MAX
sysctl -a | grep net.netfilter.nf_conntrack_max
#net.netfilter.nf_conntrack_max = 3203072
#查看当前连接跟踪表大小HASHSIZE
sysctl -a | grep net.netfilter.nf_conntrack_buckets
#400384
#或者这样
cat /sys/module/nf_conntrack/parameters/hashsize
#400384
这两个的比值即为bucket size = 3203072 / 400384
如下,现在需求是设置系统最大连接跟踪数为320w,由于bucket size不能直接设置,为了使bucket size值为8,我们需要同时设置CONNTRACK_MAX和HASHSIZE,因为他们的比值就是bucket size
#HASHSIZE (内核会自动格式化为最接近允许值)
echo 400000 > /sys/module/nf_conntrack/parameters/hashsize
#系统最大连接跟踪数
sysctl -w net.netfilter.nf_conntrack_max=3200000
#注意nf_conntrack内核模块需要加载
为了使nf_conntrack模块重新加载或系统重启后生效
#nf_conntrack模块提供了设置HASHSIZE的参数
echo "options nf_conntrack hashsize=400000" > /etc/modprobe.d/nf_conntrack.conf
只需要固化HASHSIZE值,nf_conntrack模块在重新加载时会自动设置CONNTRACK_MAX = hashsize * 8,当然前提是你bucket size使用系统默认值8。如果自定义bucket size值,就需要同时固化CONNTRACK_MAX,以保持其比值为你想要的bucket size
上面我们没有改变bucket size的默认值8,但是若内存足够并且性能很重要,你可以考虑每个bucket一个conntrack条目(bucket size = 1),最大可能降低遍历耗时,即HASHSIZE = CONNTRACK_MAX
#HASHSIZE
echo 3200000 > /sys/module/nf_conntrack/parameters/hashsize
#CONNTRACK_MAX
sysctl -w net.netfilter.nf_conntrack_max=3200000
如何计算连接跟踪所占内存
连接跟踪表存储在系统内存中,因此需要考虑内存占用问题,可以用下面公式计算设置不同的最大连接跟踪数所占最大系统内存
total_mem_used(bytes) = CONNTRACK_MAX * sizeof(struct ip_conntrack) + HASHSIZE * sizeof(struct list_head)
例如我们需要设置最大连接跟踪数为320w,在centos6/7系统上,sizeof(struct ip_conntrack) = 376,sizeof(struct list_head) = 16,并且bucket size使用默认值8,并且HASHSIZE = CONNTRACK_MAX / 8,因此
total_mem_used(bytes) = 3200000 * 376 + (3200000 / 8) * 16
# = 1153MB ~= 1GB
因此可以得到,在centos6/7系统上,设置320w的最大连接跟踪数,所消耗的内存大约为1GB,对现代服务器来说,占用内存并不多,但conntrack实在让人又爱又恨
关于上面两个sizeof(struct *)值在你系统上的大小,如果会C就好说,如果不会,可以使用如下python代码计算
import ctypes
#不同系统可能此库名不一样,需要修改
LIBNETFILTER_CONNTRACK = 'libnetfilter_conntrack.so.3.6.0'
nfct = ctypes.CDLL(LIBNETFILTER_CONNTRACK)
print 'sizeof(struct nf_conntrack):', nfct.nfct_maxsize()
print 'sizeof(struct list_head):', ctypes.sizeof(ctypes.c_void_p) * 2
conntrack条目
conntrack从经过它的数据包中提取详细的,唯一的信息,因此能保持对每一个连接的跟踪。关于conntrack如何确定一个连接,对于tcp/udp,连接由他们的源目地址,源目端口唯一确定。对于icmp,由type,code和id字段确定。
ipv4 2 tcp 6 33 SYN_SENT src=172.16.200.119 dst=172.16.202.12 sport=54786 dport=10051 [UNREPLIED] src=172.16.202.12 dst=172.16.200.119 sport=10051 dport=54786 mark=0 zone=0 use=2
如上是一条conntrack条目,它代表当前已跟踪到的某个连接,conntrack维护的所有信息都包含在这个条目中,通过它就可以知道某个连接处于什么状态
- 此连接使用ipv4协议,是一条tcp连接(tcp的协议类型代码是6)
33是这条conntrack条目在当前时间点的生存时间(每个conntrack条目都会有生存时间,从设置值开始倒计时,倒计时完后此条目将被清除),可以使用sysctl -a |grep conntrack | grep timeout查看不同协议不同状态下生存时间设置值,当然这些设置值都可以调整,注意若后续有收到属于此连接的数据包,则此生存时间将被重置(重新从设置值开始倒计时),并且状态改变,生存时间设置值也会响应改为新状态的值SYN_SENT是到此刻为止conntrack跟踪到的这个连接的状态(内核角度),SYN_SENT表示这个连接只在一个方向发送了一初始TCP SYN包,还未看到响应的SYN+ACK包(只有tcp才会有这个字段)。src=172.16.200.119 dst=172.16.202.12 sport=54786 dport=10051是从数据包中提取的此连接的源目地址、源目端口,是conntrack首次看到此数据包时候的信息。[UNREPLIED]说明此刻为止这个连接还没有收到任何响应,当一个连接已收到响应时,[UNREPLIED]标志就会被移除- 接下来的
src=172.16.202.12 dst=172.16.200.119 sport=10051 dport=54786地址和端口和前面是相反的,这部分不是数据包中带有的信息,是conntrack填充的信息,代表conntrack希望收到的响应包信息。意思是若后续conntrack跟踪到某个数据包信息与此部分匹配,则此数据包就是此连接的响应数据包。注意这部分确定了conntrack如何判断响应包(tcp/udp),icmp是依据另外几个字段
上面是tcp连接的条目,而udp和icmp没有连接建立和关闭过程,因此条目字段会有所不同,后面iptables状态匹配部分我们会看到处于各个状态的conntrack条目
注意conntrack机制并不能够修改或过滤数据包,它只是跟踪网络连接并维护连接跟踪表,以提供给iptables做状态匹配使用,也就是说,如果你iptables中用不到状态匹配,那就没必要启用conntrack
iptables状态匹配
本部分参考自iptables文档iptables-tutorial#The state machine,我找不到比它更全面的文章了
先明确下conntrack在内核协议栈所处位置,上面也提过conntrack跟踪数据包的位置在PREROUTING和OUTPUT这两个hook点,主机自身进程产生的数据包会通过OUTPUT处的conntrack,从主机任意接口进入(包括Bridge的port)的数据包会通过PREROUTING处的conntrack,从netfilter框架图上可以看到conntrack位置很靠前,仅在iptables的raw表之后,raw表主要作用就是允许我们对某些特定的数据包打上NOTRACK标记,这样后面的conntrack就不会记录此类带有NOTRACK标签的数据包。conntrack位置很靠前一方面是保证其后面的iptables表和链都能使用状态匹配,另一方面使得conntrack能够跟踪到任何进出主机的原始数据包(比如数据包还未NAT/FORWARD)。
iptables状态匹配模块
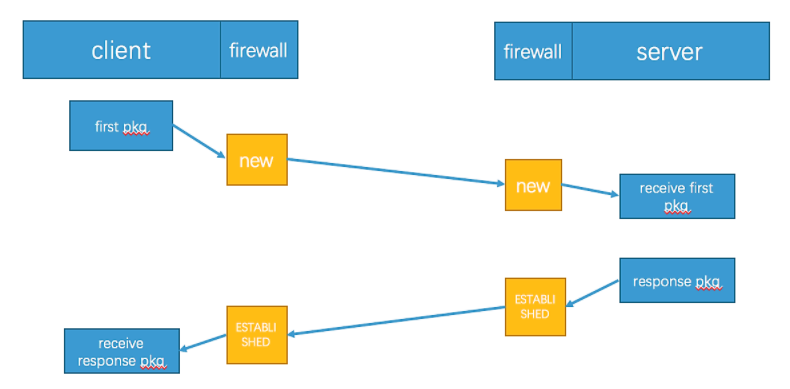
iptables是带有状态匹配的防火墙,它使用-m state模块从连接跟踪表查找数据包状态。上面我们分析的那条conntrack条目处于SYN_SENT状态,这是内核记录的状态,数据包在内核中可能会有几种不同的状态,但是映射到用户空间iptables,只有5种状态可用:NEW,ESTABLISHED,RELATED,INVALID和UNTRACKED。注意这里说的状态不是tcp/ip协议中tcp连接的各种状态。下面表格说明了这5种状态分别能够匹配什么样的数据包,注意下面两点
- 用户空间这5种状态是iptables用于完成状态匹配而定义的,不关联与特定连接协议
- conntrack记录在前,iptables匹配在后(见netfilter框架图)
| 状态 | 解释 |
|---|---|
| NEW | NEW匹配连接的第一个包。意思就是,iptables从连接跟踪表中查到此包是某连接的第一个包。判断此包是某连接的第一个包是依据conntrack当前”只看到一个方向数据包”([UNREPLIED]),不关联特定协议,因此NEW并不单指tcp连接的SYN包 |
| ESTABLISHED | ESTABLISHED匹配连接的响应包及后续的包。意思是,iptables从连接跟踪表中查到此包是属于一个已经收到响应的连接(即没有[UNREPLIED]字段)。因此在iptables状态中,只要发送并接到响应,连接就认为是ESTABLISHED的了。这个特点使iptables可以控制由谁发起的连接才可以通过,比如A与B通信,A发给B数据包属于NEW状态,B回复给A的数据包就变为ESTABLISHED状态。ICMP的错误和重定向等信息包也被看作是ESTABLISHED,只要它们是我们所发出的信息的应答。 |
| RELATED | RELATED匹配那些属于RELATED连接的包,这句话说了跟没说一样。RELATED状态有点复杂,当一个连接与另一个已经是ESTABLISHED的连接有关时,这个连接就被认为是RELATED。这意味着,一个连接要想成为RELATED,必须首先有一个已经是ESTABLISHED的连接存在。这个ESTABLISHED连接再产生一个主连接之外的新连接,这个新连接就是RELATED状态了,当然首先conntrack模块要能”读懂”它是RELATED。拿ftp来说,FTP数据传输连接就是RELATED与先前已建立的FTP控制连接,还有通过IRC的DCC连接。有了RELATED这个状态,ICMP错误消息、FTP传输、DCC等才能穿过防火墙正常工作。有些依赖此机制的TCP协议和UDP协议非常复杂,他们的连接被封装在其它的TCP或UDP包的数据部分(可以了解下overlay/vxlan/gre),这使得conntrack需要借助其它辅助模块才能正确”读懂”这些复杂数据包,比如nf_conntrack_ftp这个辅助模块 |
| INVALID | INVALID匹配那些无法识别或没有任何状态的数据包。这可能是由于系统内存不足或收到不属于任何已知连接的ICMP错误消息。一般情况下我们应该DROP此类状态的包 |
| UNTRACKED | UNTRACKED状态比较简单,它匹配那些带有NOTRACK标签的数据包。需要注意的一点是,如果你在raw表中对某些数据包设置有NOTRACK标签,那上面的4种状态将无法匹配这样的数据包,因此你需要单独考虑NOTRACK包的放行规则 |
状态的使用使防火墙可以非常强大和有效,来看下面这个常见的防火墙规则,它允许本机主动访问外网,以及放开icmp协议
#iptables-save -t filter
*filter
:INPUT DROP [1453341:537074675]
:FORWARD DROP [10976649:6291806497]
:OUTPUT ACCEPT [1221855153:247285484556]
-A INPUT -p icmp -j ACCEPT
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
主机进程与外网机器通信经历如下步骤,因为除了filter表,其它表没设置任何规则,所以下面步骤就省略其它表的匹配过程
- 进程产生要发送的数据包,数据包通过
raw表OUTPUT链(可以决定是否要NOTRACK) - 数据包通过
conntrack,conntrack记录此连接到连接跟踪表([UNREPLIED]) – NEW - 通过OUTPUT链,然后从主机网卡发出 – NEW
- 外网目标主机收到请求,发出响应包
- 响应包从主机某个接口进入,到达
raw表PREROUTING链(可以决定是否要NOTRACK) – NEW - 响应包通过
conntrack,conntrack发现此数据包为一个连接的响应包,更新对应conntrack条目状态(去掉[UNREPLIED],至此两个方向都看到包了) – ESTABLISHED - 响应包到达
filter表INPUT链,在这里匹配到--state RELATED,ESTABLISHED,因此放行 – ESTABLISHED
像上面这种允许本机主动出流量的需求,如果不用conntrack会很难实现,那你可能会说我也可以使用iptables
数据包在内核中的状态
从内核角度,不同协议有不同状态,这里我们来具体看下三种协议tcp/udp/icmp在连接跟踪表中的不同状态
tcp连接
下面是172.16.1.100向172.16.1.200建立tcp通信过程中,/proc/net/nf_conntrack中此连接的状态变化过程
ipv4 2 tcp 6 118 SYN_SENT src=172.16.1.100 dst=172.16.1.200 sport=36884 dport=8220 [UNREPLIED] src=172.16.1.200 dst=172.16.1.100 sport=8220 dport=36884 mark=0 zone=0 use=2
如上,首先172.16.1.100向172.16.1.200发送SYN包,172.16.1.200收到SYN包但尚未回复,由于是新连接,conntrack将此连接添加到连接跟踪表,并标记为SYN_SENT状态,[UNREPLIED]表示conntrack尚未跟踪到172.16.1.200的响应包。注意上面这条conntrack条目存在于两台主机的连接跟踪表中(当然,首先要两台主机都启用conntrack),对于172.16.1.100,数据包在经过OUTPUT这个hook点时触发conntrack,而对于172.16.1.200,数据包在PREROUTING这个hook点时触发conntrack
随后,172.16.1.200回复SYN/ACK包给172.16.1.100,通过conntrack更新连接状态为SYN_RECV,表示收到SYN/ACk包,去掉[UNREPLIED]字段
ipv4 2 tcp 6 59 SYN_RECV src=172.16.1.100 dst=172.16.1.200 sport=36884 dport=8220 src=172.16.1.200 dst=172.16.1.100 sport=8220 dport=36884 mark=0 zone=0 use=2
接着,172.16.1.100回复ACK给172.16.1.200,至此,三次握手完成,tcp连接已建立,conntrack更新连接状态为ESTABLISHED
ipv4 2 tcp 6 10799 ESTABLISHED src=172.16.1.100 dst=172.16.1.200 sport=36884 dport=8220 src=172.16.1.200 dst=172.16.1.100 sport=8220 dport=36884 [ASSURED] mark=0 zone=0 use=2
连接跟踪表中的conntrack条目不可能是永久存在,每个conntrack条目都有超时时间,可以如下方式查看tcp连接各个状态当前设置的超时时间
# sysctl -a |grep 'net.netfilter.nf_conntrack_tcp_timeout_'
net.netfilter.nf_conntrack_tcp_timeout_close = 10
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 60
net.netfilter.nf_conntrack_tcp_timeout_established = 432000
...
正常的tcp连接是很短暂的,不太可能查看到一个tcp连接所有状态变化的,那如何构造处于特定状态的tcp连接呢,一个方法是利用iptables的--tcp-flags参数,其可以匹配tcp数据包的标志位,比如下面这两条
#对于本机发往172.16.1.200的tcp数据包,丢弃带有SYN/ACK flag的包
iptables -A OUTPUT -o eth0 -p tcp --tcp-flags SYN,ACK SYN,ACK -d 172.16.1.200 -j DROP
#同样,这个是丢弃带有ACK flag的包
iptables -A OUTPUT -o eth0 -p tcp --tcp-flags ACK ACK -d 172.16.1.100 -j DROP
同时利用tcp超时重传机制,待cat /proc/net/nf_conntrack获取到conntrack条目后,使用iptables -D OUTPUT X删除之前设置的DROP规则,这样tcp连接就会正常走下去,这个很容易测试出来
udp连接
UDP连接是无状态的,它没有连接的建立和关闭过程,连接跟踪表中的udp连接也没有像tcp那样的状态字段,但这不妨碍用户空间iptables对udp包的状态匹配,上面也说过,iptables中使用的各个状态与协议无关
#只收到udp连接第一个包
ipv4 2 udp 17 28 src=172.16.1.100 dst=172.16.1.200 sport=26741 dport=8991 [UNREPLIED] src=172.16.1.200 dst=172.16.1.100 sport=8991 dport=26741 mark=0 zone=0 use=2
#收到此连接的响应包
ipv4 2 udp 17 29 src=172.16.1.100 dst=172.16.1.200 sport=26741 dport=8991 src=172.16.1.200 dst=172.16.1.100 sport=8991 dport=26741 mark=0 zone=0 use=2
同样可以查看udp超时时间
# sysctl -a | grep 'net.netfilter.nf_conntrack_udp_'
net.netfilter.nf_conntrack_udp_timeout = 30
net.netfilter.nf_conntrack_udp_timeout_stream = 180
icmp
icmp请求,在用户空间iptables看来,跟踪到echo request时连接处于NEW状态,当有echo reply时就是ESTABLISHED状态。
#icmp请求
ipv4 2 icmp 1 28 src=103.229.215.2 dst=113.31.136.7 type=8 code=0 id=35102 [UNREPLIED] src=113.31.136.7 dst=103.229.215.2 type=0 code=0 id=35102 mark=0 zone=0 use=2
#reply
ipv4 2 icmp 1 29 src=103.229.215.2 dst=113.31.136.7 type=8 code=0 id=35102 src=113.31.136.7 dst=103.229.215.2 type=0 code=0 id=35102 mark=0 zone=0 use=2
如何管理连接跟踪表
有一个用户空间工具conntrack,其提供了对连接跟踪表的增删改查功能,可以用yum install conntrack-tools来安装,下面是几个例子
#查看连接跟踪表所有条目
conntrack -L
#清除连接跟踪表
conntrack -F
#删除连接跟踪表中所有源地址是1.2.3.4的条目
conntrack -D -s 1.2.3.4
如果openstack使用安全组IptablesFirewallDriver就会用到这个工具,但默认不会安装,未安装时,计算节点neutron-linuxbridge-agent日志会出现类似下面错误
2018-02-14 16:59:42.755 993 ERROR neutron.agent.linux.utils [req-4f84df17-534b-4032-b907-8d3463824726 - - - - -] Rootwrap error running command: ['conntrack', '-D', '-f', 'ipv4', '-d', '172.19.3.99', '-w', '1']
2018-02-14 16:59:42.872 993 ERROR neutron.plugins.ml2.drivers.agent._common_agent self._remove_conntrack_entries_from_port_deleted(port)
需要这个工具是因为在对instance进行安全组/port/ip方面的变更后,需要同时删除连接跟踪表中旧的相关条目,比如某台instance之前放通本机80端口,某外部主机与此instance 80端口有连接并且有流量,那此时iptables从连接跟踪表中识别到此连接状态就是ESTABLISHED,然后此时突然有个需求需要禁止本机的80端口,如果不删除与本机80端口有关的处于ESTABLISHED状态的conntrack条目,而iptables又会放行处于RELATED,ESTABLISHED状态的连接,这样就会造成80端口仍能够连接
Bridge与netfilter
从netfilter框架图中可以看到,最下层蓝色区域为bridge level。Bridge的存在,使得主机可以充当一台虚拟的普通二层交换机来运作,这个虚拟交换机可以建多个port,连接到多个虚拟机。由此带来的问题是,外部机器与其上虚拟机通信流量只会经过主机二层(靠Bridge转发,此时不经过主机IP层),主机上的网卡类型变得复杂(物理网卡em1,网桥br0,虚拟网卡vnetX),进入主机的数据包可选路径变多(bridge转发/交给主机本地进程)。幸好,netfilter框架都可以解决,这部分内容在我的另一篇文章Bridge与netfilter,相信已经说得够清楚了。
conntrack与LVS
LVS的修改数据包功能也是依赖netfilter框架,在LVS机器上应用iptables时需要注意一个问题就是,LVS-DR(或LVS-Tun)模式下,不能在director上使用iptables的状态匹配(NEW,ESTABLISHED,INVALID,…)
LVS-DR模式下,client访问director,director转发流量到realserver,realserver直接回复client,不经过director,这种情况下,client与direcotr处于tcp半连接状态
因此如果在director机器上启用conntrack,此时conntrack只能看到client–>director的数据包,因为响应包不经过direcotr,conntrack无法看到反方向上的数据包,就表示iptables中的ESTABLISHED状态永远无法匹配,从而可能发生DROP
以上就是netfilter框架的内容,理论居多,后续会有一篇专门分析openstack安全组实现的文章,会包括本文大部分知识点,算是作为本文的一个实例应用
(本文完)
参考文章
Conntrack_tuning
Tuning The Linux Connection Tracking System
iptables-tutorial.html#STATEMACHINE
LVS-HOWTO:stateful filtering: LVS-DR
LVS/IPVS on Openstack - Bad Idea
conntrack_table_memory